CyberAgent20新卒AdventCalendar2019の16日目の記事です.

時系列データを分析する際によく見かける統計的な手法として移動平均というものがあります. 特に株価の推移のトレンドを測る際によく見かけますが,今回はそれを機械学習などの特徴量として使用できるような形にしたいと思います. どちらかというと実装寄りの記事です.
普段はテキストや音の解析がメインなので何か間違いがあったら指摘していただけるとありがたいです.
移動統計量と言っていますが移動平均や移動分散のことです. 実際に使われている手法としては移動平均がほとんどで移動分散と呼ばれるものは検索してもほとんどヒットしませんが,実際の現場で使用してみるとyと相関が取れたり精度向上に繋がるケースがあったため載せてみることにしました. 移動平均自体の説明は検索すると多くの記事が出てくるのでなるべく割愛しますが,時系列データでは分散によってデータの推移が見づらい場合に移動平均で平滑化することで全体的なデータの推移を見れるようにできます. 数式的には時系列データxにおける時刻tの3ステップ分の移動平均は以下のように表せます.
\frac{x_{t-2}+x_{t-1}+x_t}{3}
3ステップとしましたが,これは1日ごとのデータだったら3日分のように時系列の尺度に合わせて計算します. これの時刻tをずらしながら上記の式で移動平均を算出することで平滑化を行います.
実際のイメージとして以下の左図のような時系列データがあった時に右図のように移動平均を取ることでトレンドが把握できます.
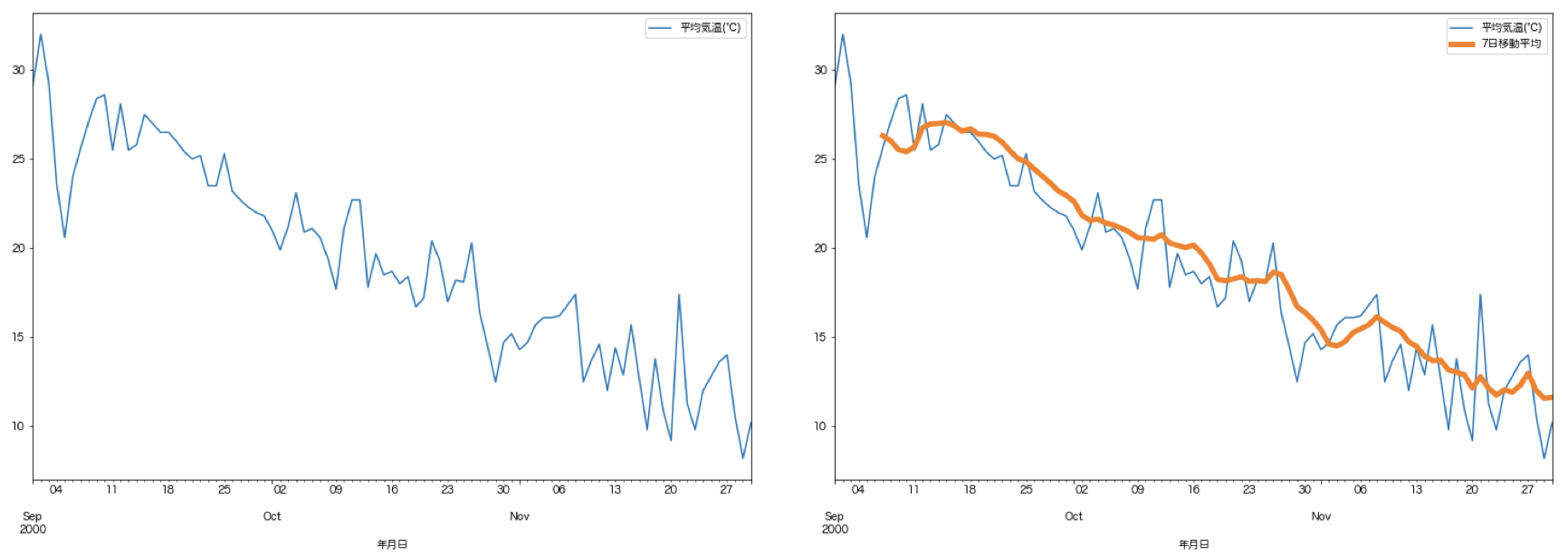
上記は単純移動平均と呼ばれるもので,移動平均にも種類があります. wikiで調べてみると以下のように種類が多いようですが,書いてあるとおり一般的には上記であげたSMA,WMA,EMAが使われるようです. それぞれ実際に手を動かして今度ユースケースを見つけたいと思います.
以前ビットコインの予測をする際に単純移動平均(SMA),加重移動平均(WMA),指数移動平均(EMA)を試したことがあり,当時は急激に下がるようなデータが無かったので現在どの指標が良いかはわかりませんが,2017年の夏頃ではSMAが一番効いた覚えがあります.実際の現場でも単純移動平均を用いています.
移動統計量を特徴量として使う際にはラグ特徴量として使わなければなりません. ラグ特徴量は,ある時刻の特徴量としてその時刻の数時間・数日前のデータを用いその時刻の指標として用います. 移動統計量ではある時点から特定のステップ前までの統計量を取る訳ですが,予測したい時刻が7日後だったりした場合,7日後の特徴量に6日後のデータは使えないため,時刻からラグ生み7日後の特徴量として現時点までの移動統計量を用います.このようにすることで学習データと予測データで特徴量を平等に扱います.
ラグ特徴量については最近だとこちらの本に書いてありますので参考までに.

データとして分かりやすかったので気象庁の日別平均気温を使用させていただきました. https://www.jma.go.jp/jma/index.html
今回は2019年11月の平均気温を予測したいという場合を考え,2000年から2018年の9・10・11月,2019年の9・10月のデータを用いることとします.

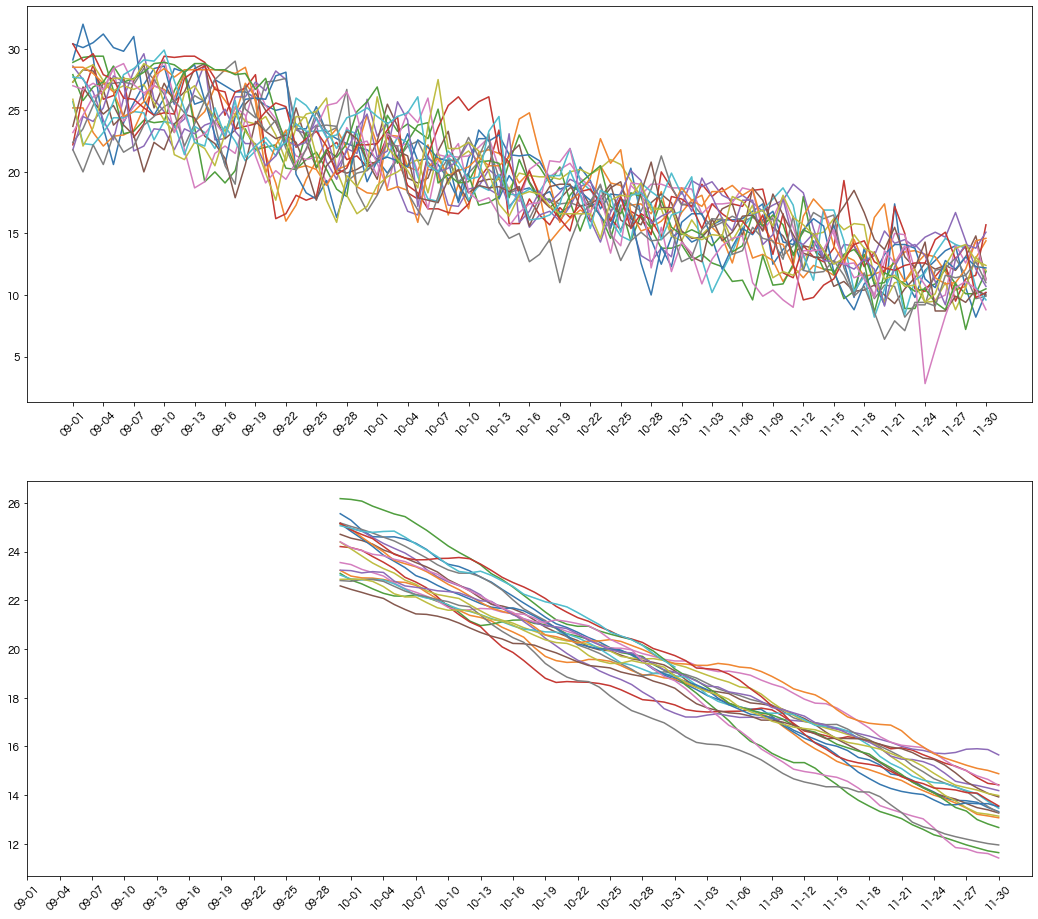
実際の値をグラフで可視化してみます.
上図が生の平均気温データで,下図が30日移動平均を取った図になります.
こうしてみると気温のばらつきがやや多い時期とそうでない時期が分かります.
移動統計量を用いる際はこの下図からさらにラグ特徴量で1ヵ月分ずらすため,学習データが少なくなってしまいます.
そのため,ラグを大きくしなくてはならない場合などには注意が必要です.
一応先のことを考え明記しておきます.
[[source]]
name = "pypi"
url = "https://pypi.org/simple"
verify_ssl = true
[dev-packages]
[packages]
pandas = "~=0.25"
matplotlib = "~=3.1"
[requires]
python_version = "3.7"
pandasではrollingという窓関数をかけられるものが備わっています. それにmeanやvarで統計量を出して,ラグ特徴を考慮してshiftで時系列をズラす形になります.
impoart pandas as pd
df = pd.read_csv('')
# sortされている前提なので適宜sortしてください
df['平均気温(℃)'].rolling(30).mean().shift(30)
# 窓関数の幅はドメインに応じてトレンドやyとの相関を見ながら決定する
pandasにはaggregate関数が用意されているので,移動平均意外にも指標を追加したい場合でも楽に追加できます.
df['平均気温(℃)'].rolling(30).agg(['mean', 'var']).shift(30)
# 尖度(kurt)や歪度(skew)も見れます.
BigQueryにも便利な窓関数が用意されているのでラグを考慮した移動平均も簡単に出せます.
SELECT
AVG(平均気温(℃)) OVER(ROWS BETWEEN 30 PRECEDING 60 PRECEDING)
FROM
`project.dataset.table`
pandasとの違いは当たり前ですがBigQueryの方が非常に早いです. 尖度歪度を計算するのはpandasほど簡単ではありませんが,特徴量として使うことは少ないので問題はないです. window関数は便利でグループごとやソートも関数適用時に指定できるので簡潔で分かりやすいです.
実データと相談しながら特徴量を見つけるのは面白いですが,まだまだ統計は初学者なのでどんどん足を踏み込んで行けたらなと思いました.