CyberAgent PTA Advent Calendar 2020 16日目の記事です.

PTAとは弊社のメディアの広告横軸組織です. PTAについて詳しくは1日目の記事をご覧ください.
本記事では広告接触UUをBigQueryMLを利用して31日先までを予測します. 今回はABEMAの純広告を想定して読んでいただけると幸いです.
広告プロダクトは広告を出稿してくださる広告主,広告を配信するメディア,配信した広告を視聴するユーザーがいて成り立ちます. (実際は広告代理店やDSP・SSPなどを挟む場合もあるのですが,今回説明としては省きます.)

広告主は広告表示回数であるimpに対し対価を払います. このとき,広告主としてはメディアの配信期間で何人のユーザーに何回配信できるか,どんなユーザーに配信できるかというターゲティング項目などの配信条件を吟味しながら広告を出稿するメディアを決めます. メディアとしてはこの広告主が望む配信条件で事前に対価をいただいて広告をユーザーに流すわけですが,その配信をしたときにどれくらいのユーザーに当てられるかということが事前に分からなければ破綻することになります. 例えとして,1impしか発生しないメディアに1000imp配信するという契約をしたらおかしいですよね.
そこで,メディアはどれくらいの広告接触の規模があるかを把握する必要があります.(この数字について広告業界では在庫と呼ぶことがあります) 弊社でもimpを予測し,実際に配信を行った際に在庫が無くなって流せないという事故が起こらないように気をつけています.
さて,本題に入りますが今年ABEMAでは広告のパーソナライズド配信が可能になりました.

これのおかげで広告を一人あたりに何回まで流すかということが制御でき,より広く広告主の要望に答えられるようになりました. この広告接触頻度(FQ)の制御ができるようになったことで,今まで以上にFQやそのUUが重視されるようになり,UUがどれくらい発生するのか推定する必要が出てきたという経緯があります.
前置きが長くなってしまいましたがBigQueryを使って予測を行っていきます. BigQueryにはデータベースの機能だけではなく,BIや機械学習(ML)の機能も盛り込まれています.
BigQueryMLは有名な機械学習モデルがいくつか用意されており,SQLを書くことでそのモデルを学習し,BigQueryのデータセット上にその学習したモデルを置いておくこともできます. 最近DNNやXGBoostなどがGAになりましたが,今もBigQueryのリソースを使って色々と開発されていそうなので期待大です.
今回はこのBigQueryMLの時系列モデルを用いて予測を行っていきます. ドキュメントにも書いてあるのですが,このモデルを使う際にBigQueryが裏側で面倒な前処理を行ってくれます.
The model automatically handles anomalies, seasonality, and holidays.
何回か時系列予測を行えば慣れますが,欠損や重複,異常値や休日までもカバーされているのでほとんど前処理をせずともモデル選択を間違えなければある程度の精度を出せるようになります. 残念ながらXGBoostなどの木で時系列予測を行うような前処理はできませんが,これだけでもすごいと思いました. 時系列モデルの詳しいドキュメントはこちらに書いてあるので読んでみると良いかもしれません.
現在時系列モデルはARIMAモデルのみ対応しています. 今回の主旨と離れるのでARIMAモデルについて詳しく説明はしませんが,自己回帰過程と移動平均過程の理解があればそれほど難しく感じないと思います. ARIMAモデルについては論文や記事が多くヒットするので調べれば分かりやすいものがあり,例えばこちらなどを参考にしてみると良いです.
一例として今回は以下のようなデータを想定します.

日付と性年齢(デモグラ)とその日のUUです. こういうデータから未来のUUを予測していきます. まずは分かりやすさのために全体のUU..
CREATE TABLE `dataset.daily_uu_table`
SELECT
date,
SUM(uu) AS daily_uu,
FROM
table
GROUP BY
date
以下のようにdateに対してuuを一意にします. ※あくまで一例なのでこういうデータ形式だと理解していただけるとありがたいです.

このデータに対してモデルの学習をします.
CREATE MODEL `dataset.model`
OPTIONS(MODEL_TYPE = 'ARIMA',
TIME_SERIES_TIMESTAMP_COL = 'date',
TIME_SERIES_DATA_COL = 'daily_uu',
DATA_FREQUENCY = 'DAILY',
HOLIDAY_REGION = 'JP'
)
AS
SELECT
date,
daily_uu,
FROM
`dataset.daily_uu_table`
これだけでauto.ARIMAのハイパーパラメーターの調整を含めたモデルの学習が実行され,AICが一番低いモデルが選ばれます.
学習されたモデルの評価指標もSQLで見ることができます.
SELECT
*
FROM
ML.EVALUATE(MODEL `dataset.model`)

評価の一部を表示していますが,KPSSテストでnon_seasonal_dが1になっているため,42種類の候補が上がっています. この結果はAICの昇順になっているので,最小値のp:1,d:1,q:1のドリフト有りモデルが選ばれたようです.
それでは予測を行います.
SELECT
*
FROM
ML.FORECAST(MODEL `dataset.model`,
STRUCT(31 AS horizon, 0.9 AS confidence_level))
horizonが予測日数,confidence_levelが信頼度を表しています.
実際に予測された結果のUUを可視化し,正解データと比較してみました.
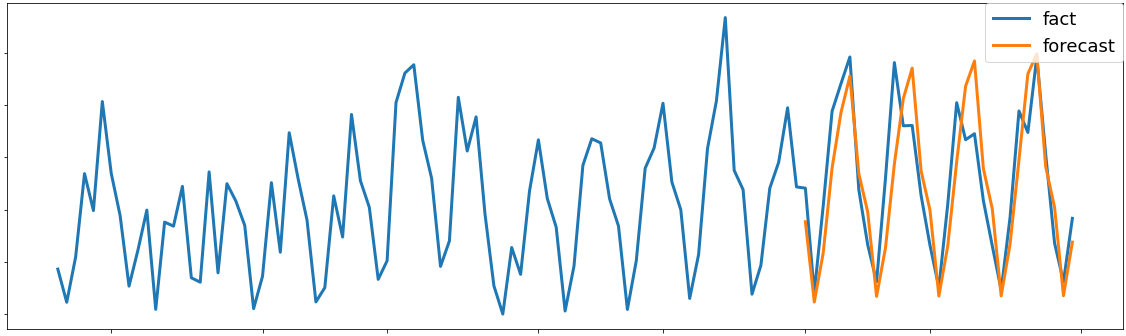 縦軸がUUで,横軸が日付です.
会社の都合上数字は出せないのですが,予測値は傾向が取れていて,精度に関しても大きくはずれるということが少なく,工夫すれば実際の運用で問題ない予測値です.
縦軸がUUで,横軸が日付です.
会社の都合上数字は出せないのですが,予測値は傾向が取れていて,精度に関しても大きくはずれるということが少なく,工夫すれば実際の運用で問題ない予測値です.
上記までは単一の時系列での予測になりますが,複数のセグメントでの予測もTIME_SERIES_ID_COLが用意されているので時系列ごとに一意なIDを指定してモデルを作成すれば時系列ごとに適切なモデルが作成されます.
今回例としては単一の時系列の予測をしましたが,複数の時系列があると他のモデルを使って精度が上がることがあります. 実際にやってみたところ時系列を比べて似たような傾向が取れ,その時系列の種類が多ければ学習データの数で精度を賄うことができました. 具体的には未来を予測するための前処理をし,そのデータをXGBoostとLSTMで学習・予測を行ったところ,一部精度向上に寄与しました. しかし,この時系列の数値を複数見比べた時に,密集した数値の時系列でしか精度が上がらず,むしろ少し他の時系列と数値が違う部分については学習データが足りず精度が下がりました.
その精度が良くなりそうな部分のみ使ってバギングしたら実際に精度は良くなりましたが,コストを考えてARIMAモデルのみで運用していく考えです.
今度APPENDIXとしてその時の前処理と学習データ生成の方法を書き足そうと思います.
最近はMLが自動化されてきて,今後はDNNの隠れ層やUNIT数も自動で調整されないかなと期待しています. 今後は業界全体的にMLで精度向上をするのではなく,MLをどう使うか,MLの根本的問題の解決をどう行うか,が主流になるのではないかなと期待しています.