この記事は「文字列アルゴリズム Advent Calendar 2017」16日目の記事です.
レーベンシュタイン距離は1965年からある古典的な文字列アルゴリズムであり,動的計画法(Dynamic Programming)で計算されることが主となっています.
また,編集距離(Edit Distance)としても知られています.
そして今回はそのレーベンシュタイン距離を算出するアルゴリズムの解説・実装・軽い応用として二つの文字列を統合したグラフを作成したいと思います.
AdventCalendarとアルゴリズムについての記事を書くことが初めてのため,間違っている点や至らないところがあれば指摘していただけると幸いです.
レーベンシュタイン距離の簡単な解説はwikipedia(レーベンシュタイン距離)を見ていただけると多少理解できると思います.
2つの文字列がどの程度似ているかを挿入・削除・置換によって一方の文字列をもう一方の文字列に変形するのに必要な手順の最小回数のことをレーベンシュタイン距離と呼びます.
長さnと長さmの文字列のレーベンシュタイン距離を算出する場合には(n+1)×(m+1)行列を作成します.
例としてagentとagencyで行うと6×7の行列を生成します.
しかし比べる対象が列に来た方が個人的に見やすく感じたので反転させて6×7の行列として計算を行なっています.
まずは挿入、削除、置換のコストを決め、そのコストで表を左上から右下にかけて計算を行なっていきます.
今回はそれぞれのコストを
とします.
表を埋めていくにあたって
表の下へ進むのが挿入,右へ進むのが削除.
右下へ進むのが正解か置換となります.
右下へ進む場合には行と列で文字を比較し一致していたら0,一致していない場合は置換として10を表へ入力します.
表へ数値を埋める時に上記の4パターンがぶつかると思いますが、それぞれの最小値をそのセルまでのコストとして計算していきます.
一般化すると

計算量的には$O(mn)$と最近では大きいと言う方も多いと思うのでビームサーチなどで減らしても良いかと思います.
それでは表に初期値を入力していきます.

それからコストを計算し、一番小さくなるような値を表へ埋めていきます.
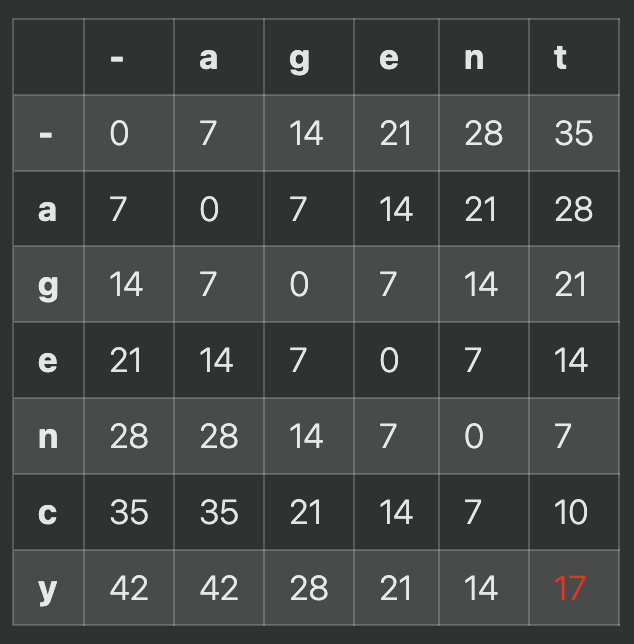
このようになり、レーベンシュタイン距離は1番右下の17という数値になります.
実際に計算する場合は各セルの値がどこのセルから遷移してきたかを情報として取っておくと文字列がどう対応しているのかが分かるので後から分かりやすくなります。
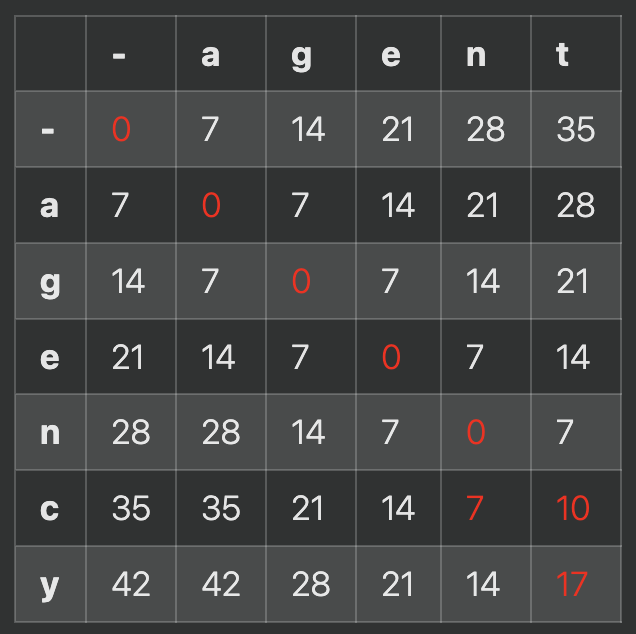
今回はagencyのcが挿入、yがagentのtと置換の場合と agencyのcがagentのtと置換、yが挿入の場合の2パターンできます。
この計算を実装したいと思います。 今回は普段あまり使っていないpythonで実装してみました。
まずは環境から
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.12.6
BuildVersion: 16G29
$ python --version
Python 3.6.3
今回は複数パターンあってもその中の1パターンだけ算出しています。
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from sys import argv, exit
from typing import Tuple, List
dict = {'m': 'match', 'i': 'insertion', 'd': 'deletion', 'r': 'replacement'}
def validation_argv() -> None:
if len(argv) < 3:
exit('Less arguments...\n' + 'should $' + argv[0] + ' "text1" "text2"')
for index in range(1, 2):
if type(argv[index]) is not str:
exit('Argument must be string')
def initialize_table(word1: str, word2: str) -> List[List[Tuple[int, int, int]]]:
# (スコア, 遷移前の座標x(row), 遷移前の座標y(column))
table = [[(0, 0, 0)] * (len(word1) + 1) for i in range(len(word2) + 1)]
for column in range(1, len(table[0])):
table[0][column] = table[0][column - 1][0] + 7, 0, column - 1
for row in range(1, len(table)):
table[row][0] = table[row - 1][0][0] + 7, row - 1, 0
return table
def calculate_cost(table: List[List[Tuple[int, int, int]]], word1: str, word2: str) -> List[List[Tuple[int, int, int]]]:
for row in range(1, len(table)):
for column in range(1, len(table[0])):
if word1[column - 1] == word2[row - 1]:
table[row][column] = table[row - 1][column - 1][0], row - 1, column - 1
else:
up_left = (table[row - 1][column - 1][0] + 10, row - 1, column - 1)
left = (table[row][column - 1][0] + 7, row, column - 1)
up = (table[row - 1][column][0] + 7, row - 1, column)
table[row][column] = sorted([up_left, left, up], key=lambda x: x[0])[0]
return table
def print_table(table: List[List[Tuple[int, int, int]]]) -> None:
for row in table:
print(row)
# テーブルのコストを元にレーベンシュタイン距離の編集操作を判断
def judge_result(table: List[List[Tuple[int, int, int]]], word1: str, word2: str) -> List[Tuple[str, str]]:
results = []
follow = (len(word2), len(word1))
while follow != (0, 0):
point = table[follow[0]][follow[1]]
route = (point[1], point[2])
if follow[0] == route[0]:
results.append(([word1[route[1]]], 'd'))
elif follow[1] == route[1]:
results.append(([word2[route[0]]], 'i'))
elif table[route[0]][route[1]][0] == point[0]:
results.append(([word1[route[1]]], 'm'))
else:
results.append(([word1[route[1]], word2[route[0]]], 'r'))
follow = route
results.reverse()
return results
def print_results(results: List[Tuple[str, str]]) -> None:
for result in results:
print(result[0], ': ', dict[result[1]])
if __name__ == '__main__':
validation_argv()
word1, word2 = argv[1], argv[2]
table = initialize_table(word1, word2)
calculated_table = calculate_cost(table, word1, word2)
print_table(calculated_table)
results = judge_result(calculated_table, word1, word2)
print_results(results)
$ python levenshtein.py agent agency
[(0, 0, 0), (7, 0, 0), (14, 0, 1), (21, 0, 2), (28, 0, 3), (35, 0, 4)]
[(7, 0, 0), (0, 0, 0), (7, 1, 1), (14, 1, 2), (21, 1, 3), (28, 1, 4)]
[(14, 1, 0), (7, 1, 1), (0, 1, 1), (7, 2, 2), (14, 2, 3), (21, 2, 4)]
[(21, 2, 0), (14, 2, 1), (7, 2, 2), (0, 2, 2), (7, 3, 3), (14, 3, 4)]
[(28, 3, 0), (21, 3, 1), (14, 3, 2), (7, 3, 3), (0, 3, 3), (7, 4, 4)]
[(35, 4, 0), (28, 4, 1), (21, 4, 2), (14, 4, 3), (7, 4, 4), (10, 4, 4)]
[(42, 5, 0), (35, 5, 1), (28, 5, 2), (21, 5, 3), (14, 5, 4), (17, 5, 4)]
['a'] : match
['g'] : match
['e'] : match
['n'] : match
['c'] : insertion
['t', 'y'] : replacement
あまり時間かけず作成してしまったので無駄な部分や分かりづらい点が多くありそうです...
分かりやすさ重視ならclassにしたりした方が良いのでしょうか.
1度pythonでできているサービスのコードを読んでみたいです.
上記のレーベンシュタイン距離のコードの結果からグラフを作成するようなコードを書きたいと思います.
今回は使いやすそうだったgraphvizというものを使います.
これはDOT言語というものを使っていて特定の形式のファイルから画像を生成してくれる便利なものです.
ちょっと試しに使ってみたので詳しくはわからないです.
graphvizの本体とpython用のライブラリを用意していきます.
$ brew install graphviz
$ dot -V # インストールできていることを確認
dot - graphviz version 2.40.1 (20161225.0304)
$ pip install graphviz
# インストールできていることを確認
$ python
Python 3.6.3 (default, Nov 29 2017, 03:13:00)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.37)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import graphviz
>>> # エラーがでなければ成功
#! /usr/bin/env python
# -*- coding: utf-8 -*-
from sys import argv, exit
from typing import Tuple, List
from graphviz import Digraph
dict = {'m': 'match', 'i': 'insertion', 'd': 'deletion', 'r': 'replacement'}
def validation_argv() -> None:
if len(argv) < 3:
exit('Less arguments...\n' + 'should $' + argv[0] + ' "text1" "text2"')
for index in range(1, 2):
if type(argv[index]) is not str:
exit('Argument must be string')
def initialize_table(word1: str, word2: str) -> List[List[Tuple[int, int, int]]]:
# (スコア, 遷移前の座標x(row), 遷移前の座標y(column))
table = [[(0, 0, 0)] * (len(word1) + 1) for i in range(len(word2) + 1)]
for column in range(1, len(table[0])):
table[0][column] = table[0][column - 1][0] + 7, 0, column - 1
for row in range(1, len(table)):
table[row][0] = table[row - 1][0][0] + 7, row - 1, 0
return table
def calculate_cost(table: List[List[Tuple[int, int, int]]], word1: str, word2: str) -> List[List[Tuple[int, int, int]]]:
for row in range(1, len(table)):
for column in range(1, len(table[0])):
if word1[column - 1] == word2[row - 1]:
table[row][column] = table[row - 1][column - 1][0], row - 1, column - 1
else:
up_left = (table[row - 1][column - 1][0] + 10, row - 1, column - 1)
left = (table[row][column - 1][0] + 7, row, column - 1)
up = (table[row - 1][column][0] + 7, row - 1, column)
table[row][column] = sorted([up_left, left, up], key=lambda x: x[0])[0]
return table
def print_table(table: List[List[Tuple[int, int, int]]]) -> None:
for row in table:
print(row)
# テーブルのコストを元にレーベンシュタイン距離の編集操作を判断
def judge_result(table: List[List[Tuple[int, int, int]]], word1: str, word2: str) -> List[Tuple[str, str]]:
results = []
follow = (len(word2), len(word1))
while follow != (0, 0):
point = table[follow[0]][follow[1]]
route = (point[1], point[2])
if follow[0] == route[0]:
results.append(([word1[route[1]]], 'd'))
elif follow[1] == route[1]:
results.append(([word2[route[0]]], 'i'))
elif table[route[0]][route[1]][0] == point[0]:
results.append(([word1[route[1]]], 'm'))
else:
results.append(([word1[route[1]], word2[route[0]]], 'r'))
follow = route
results.reverse()
return results
def print_results(results: List[Tuple[str, str]]) -> None:
for result in results:
print(result[0], ': ', dict[result[1]])
def make_graph(results: List[Tuple[str, str]]) -> None:
graph = Digraph(format="png")
graph.attr("node", shape="record", style="filled")
graph.node("start", shape="circle", color="pink")
graph.node("end", shape="circle", color="pink")
name_list = ["start"]
num = 1
branch_status = {}
for result in results:
node_name = 'node' + str(num)
graph.node(node_name, label='|'.join(result[0]))
status = result[1]
if status in ['r', 'm']:
for name in name_list:
graph.edge(name, node_name, label=dict[status])
name_list = [node_name]
branch_status = {}
elif status in ['d', 'i']:
if status in branch_status:
graph.edge(branch_status[status], node_name, label=dict[status])
name_list.remove(branch_status[status])
else:
graph.edge(name_list[0], node_name, label=dict[status])
name_list.append(node_name)
branch_status[status] = node_name
num += 1
for name in name_list:
graph.edge(name, 'end')
graph.render("graphs")
if __name__ == '__main__':
validation_argv()
word1, word2 = argv[1], argv[2]
table = initialize_table(word1, word2)
calculated_table = calculate_cost(table, word1, word2)
print_table(calculated_table)
results = judge_result(calculated_table, word1, word2)
print_results(results)
make_graph(results)
実行します。
$ python levenshtein_graph.py agent agency
[(0, 0, 0), (7, 0, 0), (14, 0, 1), (21, 0, 2), (28, 0, 3), (35, 0, 4)]
[(7, 0, 0), (0, 0, 0), (7, 1, 1), (14, 1, 2), (21, 1, 3), (28, 1, 4)]
[(14, 1, 0), (7, 1, 1), (0, 1, 1), (7, 2, 2), (14, 2, 3), (21, 2, 4)]
[(21, 2, 0), (14, 2, 1), (7, 2, 2), (0, 2, 2), (7, 3, 3), (14, 3, 4)]
[(28, 3, 0), (21, 3, 1), (14, 3, 2), (7, 3, 3), (0, 3, 3), (7, 4, 4)]
[(35, 4, 0), (28, 4, 1), (21, 4, 2), (14, 4, 3), (7, 4, 4), (10, 4, 4)]
[(42, 5, 0), (35, 5, 1), (28, 5, 2), (21, 5, 3), (14, 5, 4), (17, 5, 4)]
['a'] : match
['g'] : match
['e'] : match
['n'] : match
['c'] : insertion
['t', 'y'] : replacement
ターミナルでの実行結果は変わりませんが,ディレクトリにgraphsというDOT言語形式のファイルとgraphs.pngというグラフと画像ファイルが生成されているはずです.
digraph {
node [shape=record style=filled]
start [color=pink shape=circle]
end [color=pink shape=circle]
node1 [label=a]
start -> node1 [label=match]
node2 [label=g]
node1 -> node2 [label=match]
node3 [label=e]
node2 -> node3 [label=match]
node4 [label=n]
node3 -> node4 [label=match]
node5 [label=c]
node4 -> node5 [label=insertion]
node6 [label="t|y"]
node4 -> node6 [label=replacement]
node5 -> node6 [label=replacement]
node6 -> end
}
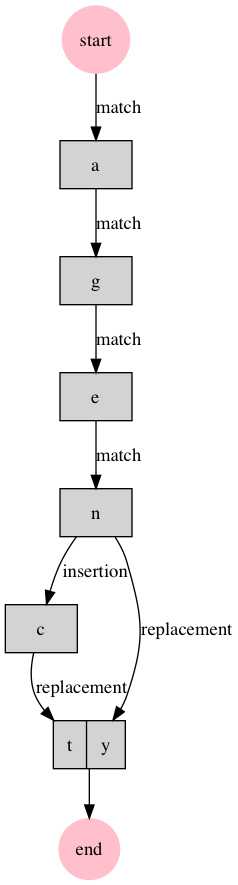
今回は簡単な文字列の実装でしか試していませんが,文同士の比較などで今回のグラフ作成をすると2つの文の比較が視覚化されて分かりやすくなるのではないかと思います.
結構昔の手法でも工夫すればまた違った見え方がして面白いなと思いました.
以上 レーベンシュタイン距離の編集操作を統合してグラフ化する でした。